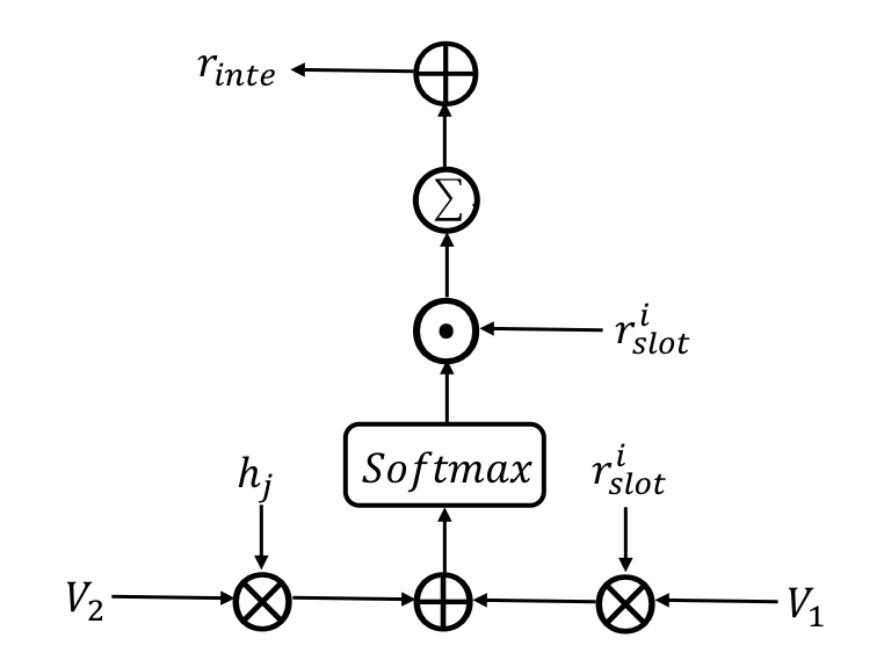
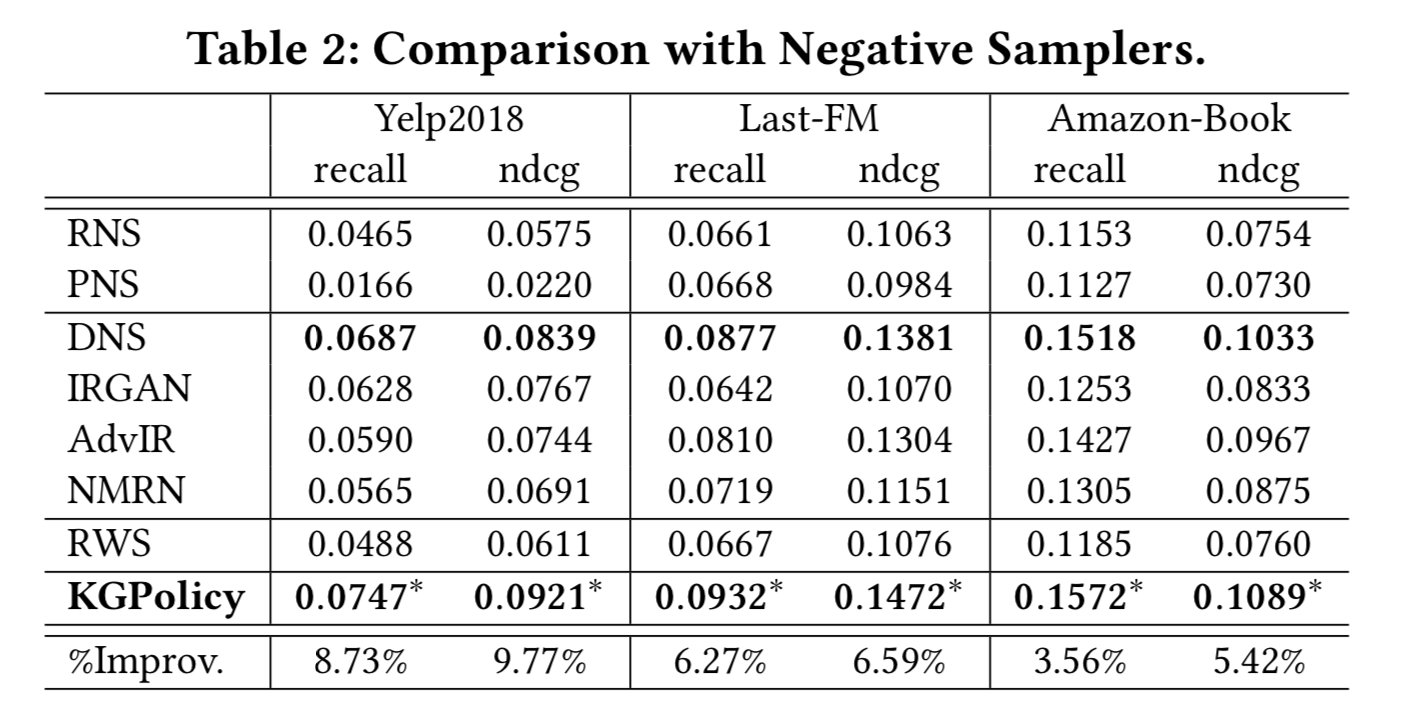
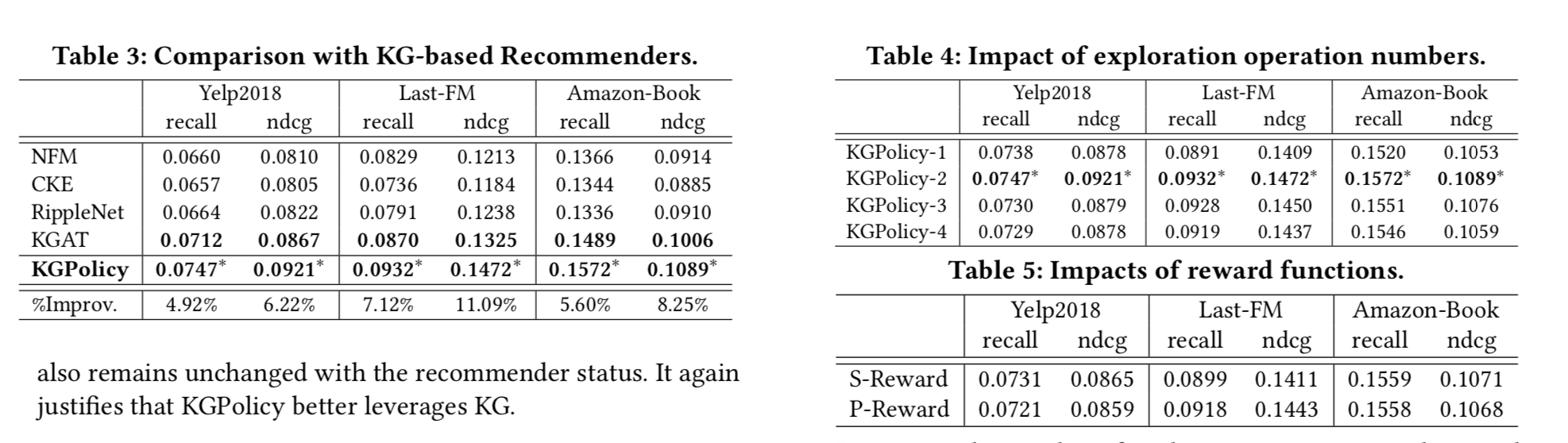
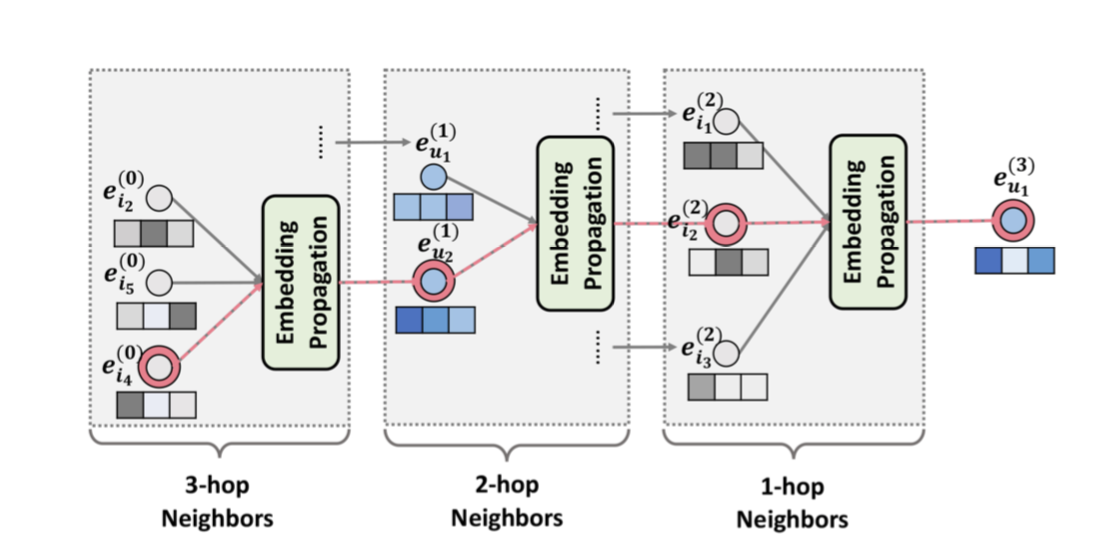
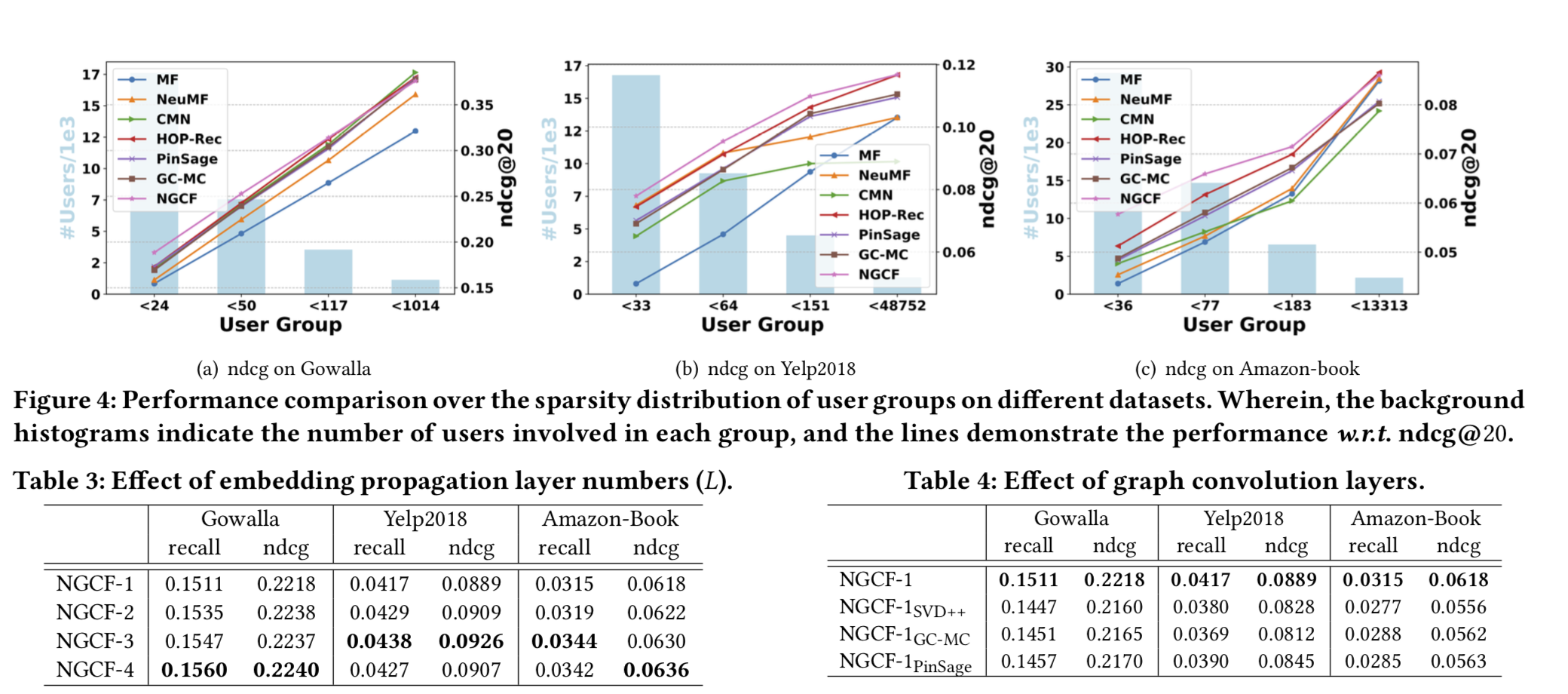
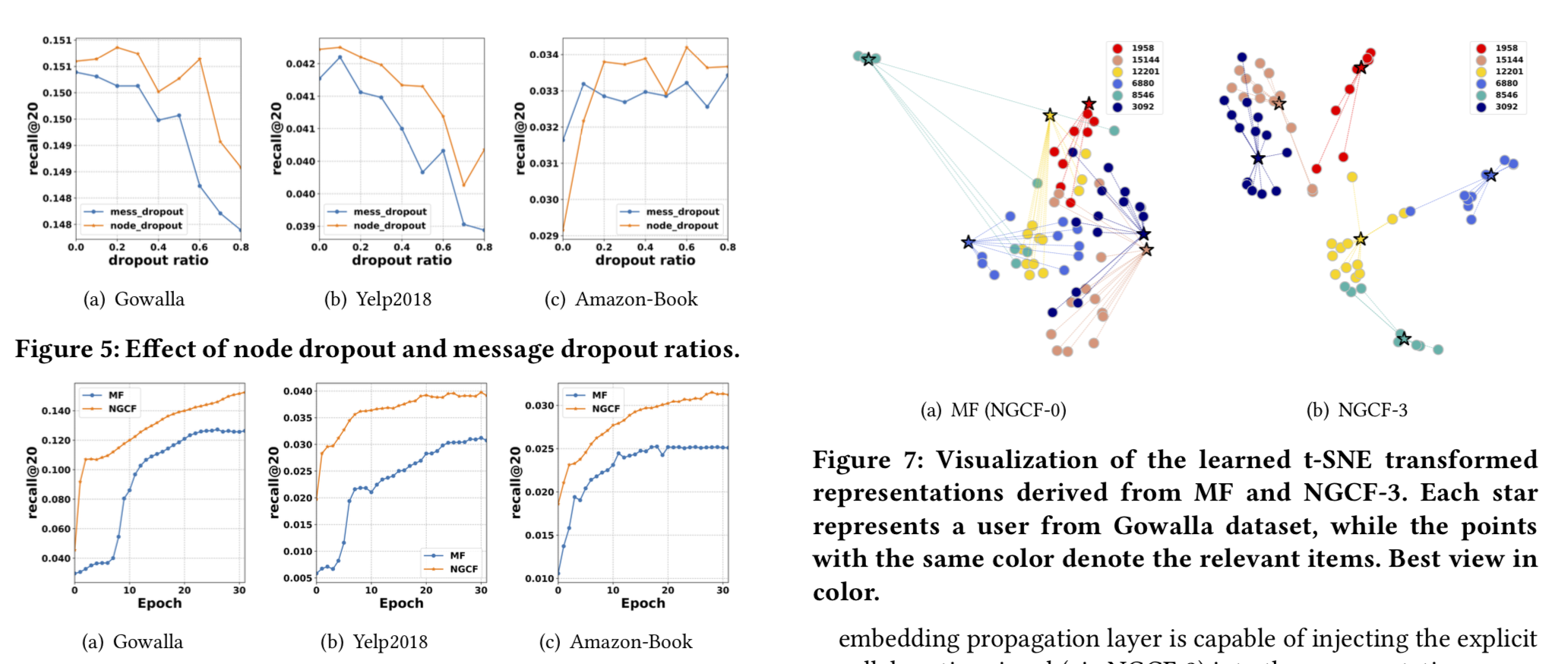
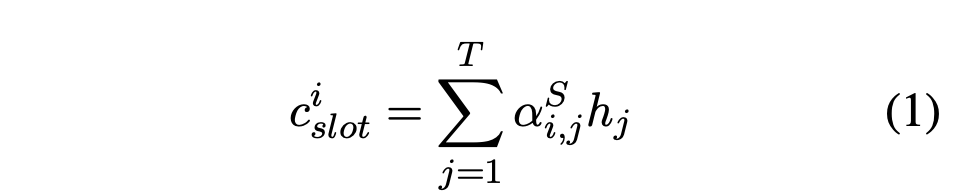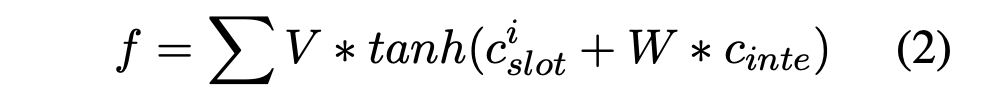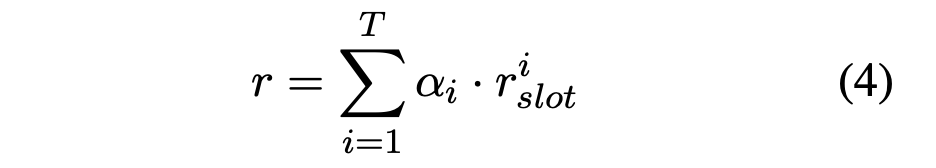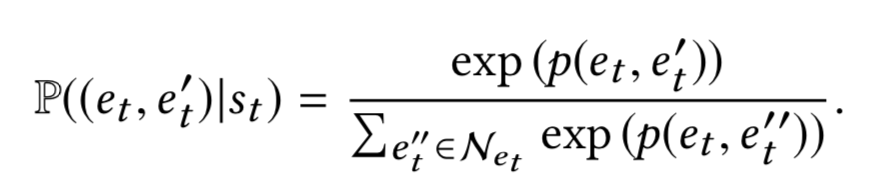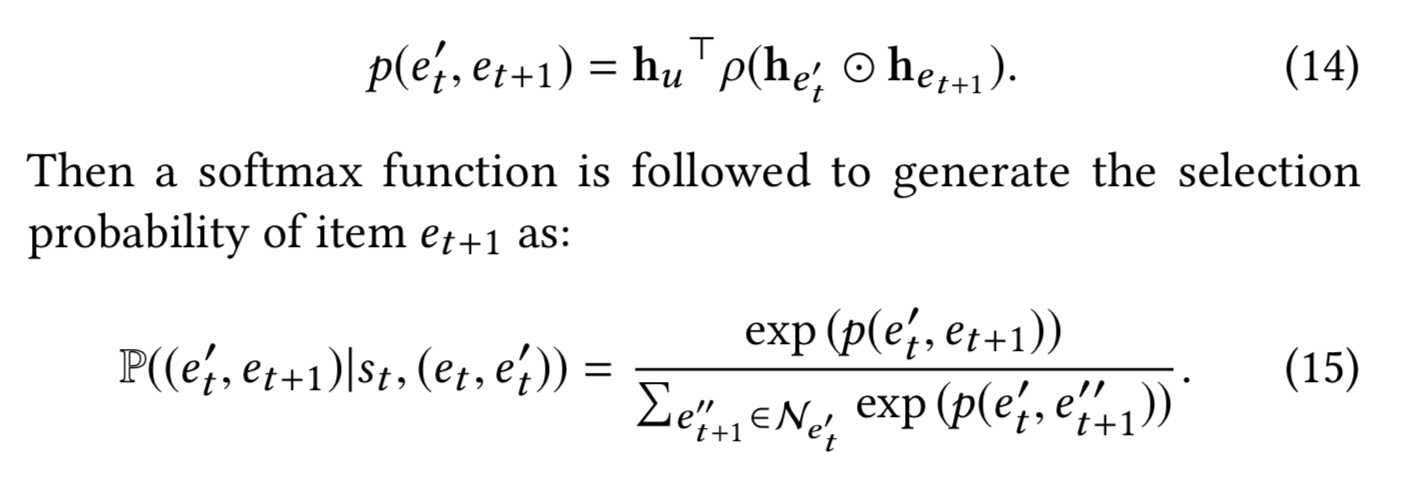1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
| import torch
import torch.nn as nn
from torch.nn import Module
from scipy.sparse import coo_matrix
from scipy.sparse import vstack
from scipy import sparse
import numpy as np
class SVD(Module):
def __init__(self,userNum,itemNum,dim):
super(SVD, self).__init__()
self.uEmbd = nn.Embedding(userNum,dim)
self.iEmbd = nn.Embedding(itemNum,dim)
self.uBias = nn.Embedding(userNum,1)
self.iBias = nn.Embedding(itemNum,1)
self.overAllBias = nn.Parameter(torch.Tensor([0]))
def forward(self, userIdx,itemIdx):
uembd = self.uEmbd(userIdx)
iembd = self.iEmbd(itemIdx)
ubias = self.uBias(userIdx)
ibias = self.iBias(itemIdx)
biases = ubias + ibias + self.overAllBias
prediction = torch.sum(torch.mul(uembd,iembd),dim=1) + biases.flatten()
return prediction
class NCF(Module):
def __init__(self,userNum,itemNum,dim,layers=[128,64,32,8]):
super(NCF, self).__init__()
self.uEmbd = nn.Embedding(userNum,dim)
self.iEmbd = nn.Embedding(itemNum,dim)
self.fc_layers = torch.nn.ModuleList()
self.finalLayer = torch.nn.Linear(layers[-1],1)
for From,To in zip(layers[:-1],layers[1:]):
self.fc_layers.append(nn.Linear(From,To))
def forward(self, userIdx,itemIdx):
uembd = self.uEmbd(userIdx)
iembd = self.iEmbd(itemIdx)
embd = torch.cat([uembd, iembd], dim=1)
x = embd
for l in self.fc_layers:
x = l(x)
x = nn.ReLU()(x)
prediction = self.finalLayer(x)
return prediction.flatten()
class GNNLayer(Module):
def __init__(self,inF,outF):
super(GNNLayer,self).__init__()
self.inF = inF
self.outF = outF
self.linear = torch.nn.Linear(in_features=inF,out_features=outF)
self.interActTransform = torch.nn.Linear(in_features=inF,out_features=outF)
def forward(self, laplacianMat,selfLoop,features):
# for GCF ajdMat is a (N+M) by (N+M) mat
# laplacianMat L = D^-1(A)D^-1 # 拉普拉斯矩阵
L1 = laplacianMat + selfLoop
L2 = laplacianMat.cuda()
L1 = L1.cuda()
inter_feature = torch.sparse.mm(L2,features)
inter_feature = torch.mul(inter_feature,features)
inter_part1 = self.linear(torch.sparse.mm(L1,features))
inter_part2 = self.interActTransform(torch.sparse.mm(L2,inter_feature))
return inter_part1+inter_part2
class GCF(Module):
def __init__(self,userNum,itemNum,rt,embedSize=100,layers=[100,80,50],useCuda=True):
super(GCF,self).__init__()
self.useCuda = useCuda
self.userNum = userNum
self.itemNum = itemNum
self.uEmbd = nn.Embedding(userNum,embedSize)
self.iEmbd = nn.Embedding(itemNum,embedSize)
self.GNNlayers = torch.nn.ModuleList()
self.LaplacianMat = self.buildLaplacianMat(rt) # sparse format
self.leakyRelu = nn.LeakyReLU()
self.selfLoop = self.getSparseEye(self.userNum+self.itemNum)
self.transForm1 = nn.Linear(in_features=layers[-1]*(len(layers))*2,out_features=64)
self.transForm2 = nn.Linear(in_features=64,out_features=32)
self.transForm3 = nn.Linear(in_features=32,out_features=1)
for From,To in zip(layers[:-1],layers[1:]):
self.GNNlayers.append(GNNLayer(From,To))
def getSparseEye(self,num):
i = torch.LongTensor([[k for k in range(0,num)],[j for j in range(0,num)]])
val = torch.FloatTensor([1]*num)
return torch.sparse.FloatTensor(i,val)
def buildLaplacianMat(self,rt):
rt_item = rt['itemId'] + self.userNum
uiMat = coo_matrix((rt['rating'], (rt['userId'], rt['itemId'])))
uiMat_upperPart = coo_matrix((rt['rating'], (rt['userId'], rt_item)))
uiMat = uiMat.transpose()
uiMat.resize((self.itemNum, self.userNum + self.itemNum))
A = sparse.vstack([uiMat_upperPart,uiMat])
selfLoop = sparse.eye(self.userNum+self.itemNum)
sumArr = (A>0).sum(axis=1)
diag = list(np.array(sumArr.flatten())[0])
diag = np.power(diag,-0.5)
D = sparse.diags(diag)
L = D * A * D
L = sparse.coo_matrix(L)
row = L.row
col = L.col
i = torch.LongTensor([row,col])
data = torch.FloatTensor(L.data)
SparseL = torch.sparse.FloatTensor(i,data)
return SparseL
def getFeatureMat(self):
uidx = torch.LongTensor([i for i in range(self.userNum)])
iidx = torch.LongTensor([i for i in range(self.itemNum)])
if self.useCuda == True:
uidx = uidx.cuda()
iidx = iidx.cuda()
userEmbd = self.uEmbd(uidx)
itemEmbd = self.iEmbd(iidx)
features = torch.cat([userEmbd,itemEmbd],dim=0)
return features
def forward(self,userIdx,itemIdx):
itemIdx = itemIdx + self.userNum
userIdx = list(userIdx.cpu().data)
itemIdx = list(itemIdx.cpu().data)
# gcf data propagation
features = self.getFeatureMat()
finalEmbd = features.clone()
for gnn in self.GNNlayers:
features = gnn(self.LaplacianMat,self.selfLoop,features)
features = nn.ReLU()(features)
finalEmbd = torch.cat([finalEmbd,features.clone()],dim=1)
userEmbd = finalEmbd[userIdx]
itemEmbd = finalEmbd[itemIdx]
embd = torch.cat([userEmbd,itemEmbd],dim=1)
embd = nn.ReLU()(self.transForm1(embd))
embd = self.transForm2(embd)
embd = self.transForm3(embd)
prediction = embd.flatten()
return prediction
|