1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
| import math
import torch
import torch.nn as nn
class PhasedLSTMCell(nn.Module):
"""Phased LSTM recurrent network cell.
https://arxiv.org/pdf/1610.09513v1.pdf
"""
def __init__(
self,
hidden_size,
leak=0.001,
ratio_on=0.1,
period_init_min=1.0,
period_init_max=1000.0
):
"""
Args:
hidden_size: int, The number of units in the Phased LSTM cell.
leak: float or scalar float Tensor with value in [0, 1]. Leak applied
during training.
ratio_on: float or scalar float Tensor with value in [0, 1]. Ratio of the
period during which the gates are open.
period_init_min: float or scalar float Tensor. With value > 0.
Minimum value of the initialized period.
The period values are initialized by drawing from the distribution:
e^U(log(period_init_min), log(period_init_max))
Where U(.,.) is the uniform distribution.
period_init_max: float or scalar float Tensor.
With value > period_init_min. Maximum value of the initialized period.
"""
super().__init__()
self.hidden_size = hidden_size
self.ratio_on = ratio_on
self.leak = leak
# initialize time-gating parameters
period = torch.exp(
torch.Tensor(hidden_size).uniform_(
math.log(period_init_min), math.log(period_init_max)
)
)
self.tau = nn.Parameter(period)
phase = torch.Tensor(hidden_size).uniform_() * period
self.phase = nn.Parameter(phase)
def _compute_phi(self, t):
t_ = t.view(-1, 1).repeat(1, self.hidden_size)
phase_ = self.phase.view(1, -1).repeat(t.shape[0], 1)
tau_ = self.tau.view(1, -1).repeat(t.shape[0], 1)
phi = torch.fmod((t_ - phase_), tau_).detach()
phi = torch.abs(phi) / tau_
return phi
def _mod(self, x, y):
"""Modulo function that propagates x gradients."""
return x + (torch.fmod(x, y) - x).detach()
def set_state(self, c, h):
self.h0 = h
self.c0 = c
def forward(self, c_s, h_s, t):
# print(c_s.size(), h_s.size(), t.size())
phi = self._compute_phi(t)
# Phase-related augmentations
k_up = 2 * phi / self.ratio_on
k_down = 2 - k_up
k_closed = self.leak * phi
k = torch.where(phi < self.ratio_on, k_down, k_closed)
k = torch.where(phi < 0.5 * self.ratio_on, k_up, k)
k = k.view(c_s.shape[0], t.shape[0], -1)
c_s_new = k * c_s + (1 - k) * self.c0
h_s_new = k * h_s + (1 - k) * self.h0
return h_s_new, c_s_new
class PhasedLSTM(nn.Module):
"""Wrapper for multi-layer sequence forwarding via
PhasedLSTMCell"""
def __init__(
self,
input_size,
hidden_size,
bidirectional=True
):
super().__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
bidirectional=bidirectional,
batch_first=True
)
self.bi = 2 if bidirectional else 1
self.phased_cell = PhasedLSTMCell(
hidden_size=self.bi * hidden_size
)
def forward(self, u_sequence):
"""
Args:
sequence: The input sequence data of shape (batch, time, N)
times: The timestamps corresponding to the data of shape (batch, time)
"""
c0 = u_sequence.new_zeros((self.bi, u_sequence.size(0), self.hidden_size))
h0 = u_sequence.new_zeros((self.bi, u_sequence.size(0), self.hidden_size))
self.phased_cell.set_state(c0, h0)
outputs = []
for i in range(u_sequence.size(1)):
u_t = u_sequence[:, i, :-1].unsqueeze(1)
t_t = u_sequence[:, i, -1]
out, (c_t, h_t) = self.lstm(u_t, (c0, h0))
(c_s, h_s) = self.phased_cell(c_t, h_t, t_t)
self.phased_cell.set_state(c_s, h_s)
c0, h0 = c_s, h_s
outputs.append(out)
outputs = torch.cat(outputs, dim=1)
return outputs
|
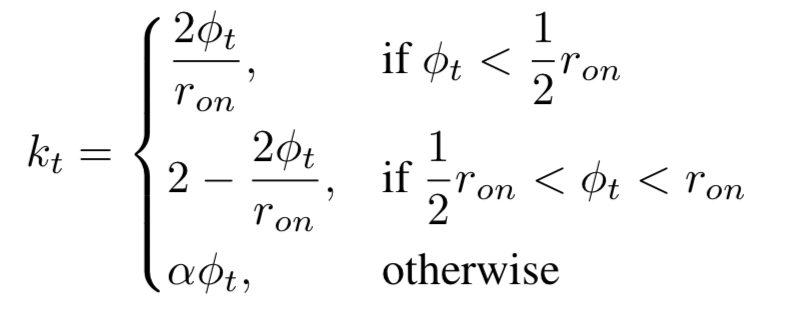 所以phased_lstm的公式还需要time gate的更新:
所以phased_lstm的公式还需要time gate的更新:
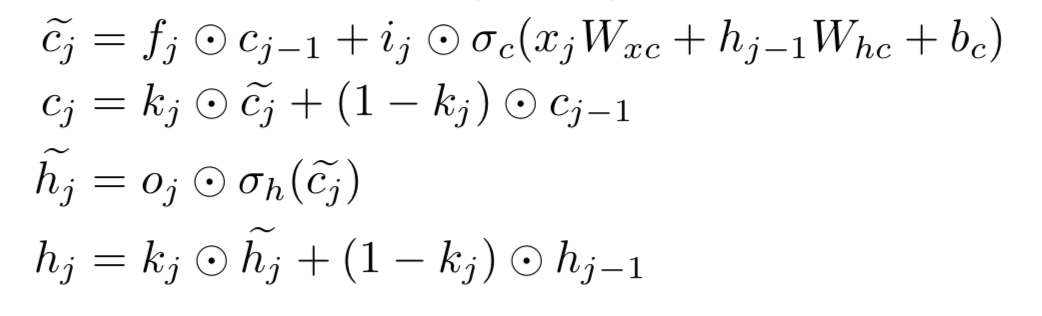 Phased LSTM还有一个好处, 它能更好地保持初始信息。
传统的lstm:
Phased LSTM还有一个好处, 它能更好地保持初始信息。
传统的lstm:
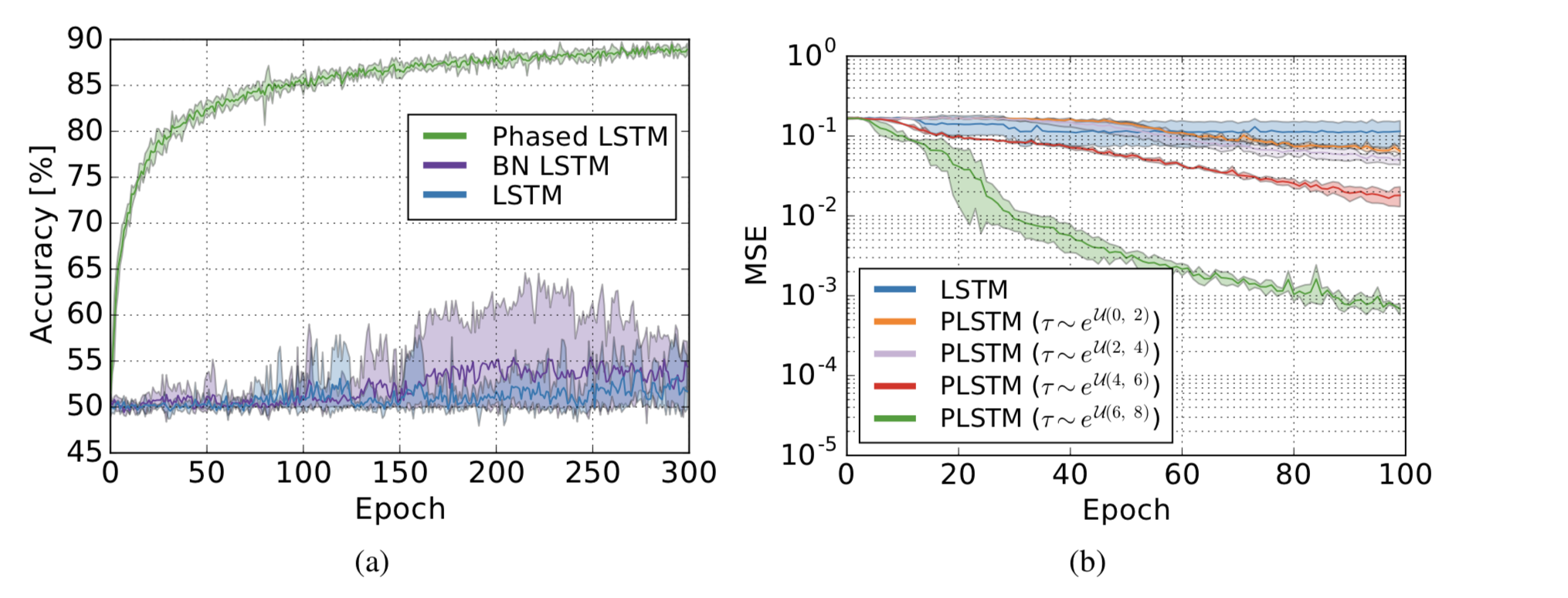 可以看到在一些数据集上其实效果远胜传统的lstm,具体可查看原论文。
可以看到在一些数据集上其实效果远胜传统的lstm,具体可查看原论文。
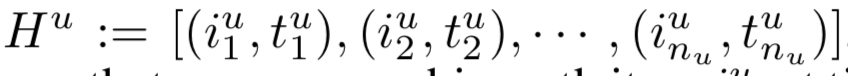 实际建模时会把单点的时间转换为时间间隔建模。
实际建模时会把单点的时间转换为时间间隔建模。
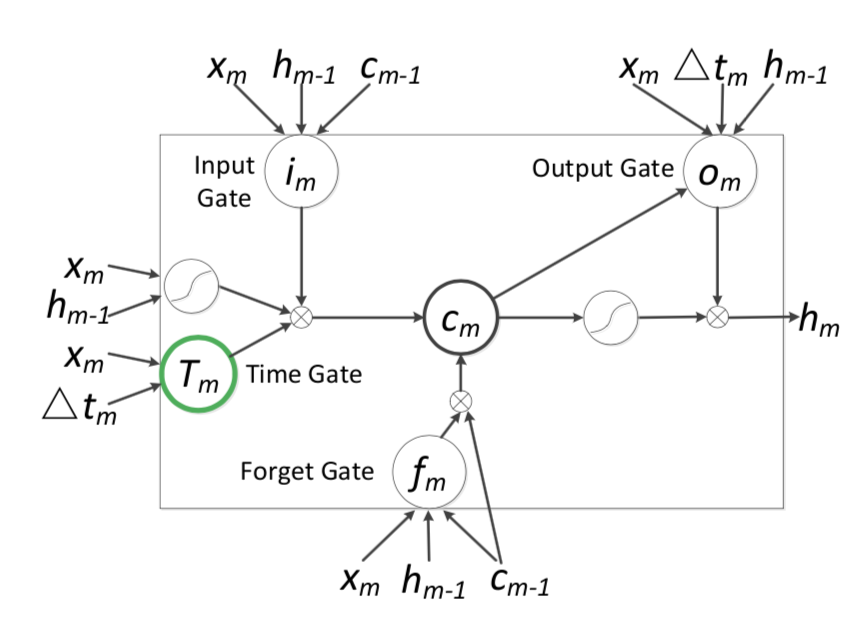
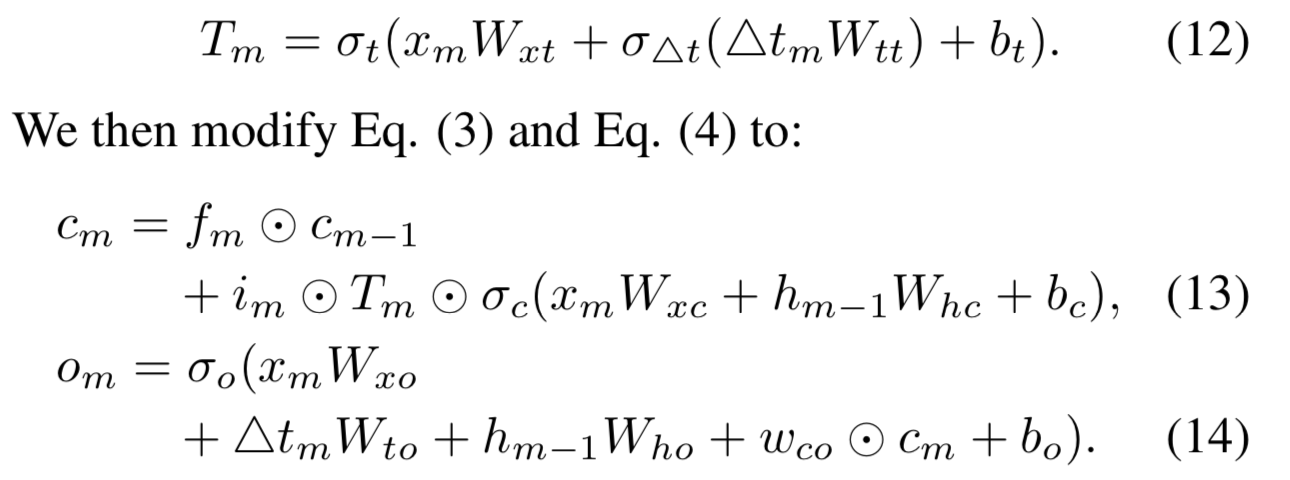 这是Phased LSTM最简单的改变,仅仅是把时间点换成了时间间隔,非常清晰易懂。
这是Phased LSTM最简单的改变,仅仅是把时间点换成了时间间隔,非常清晰易懂。
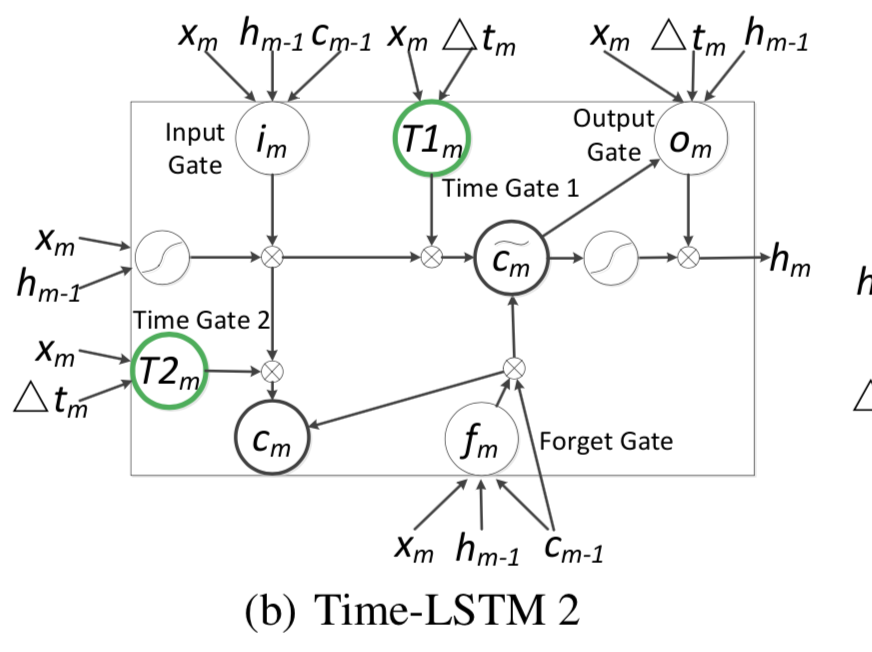
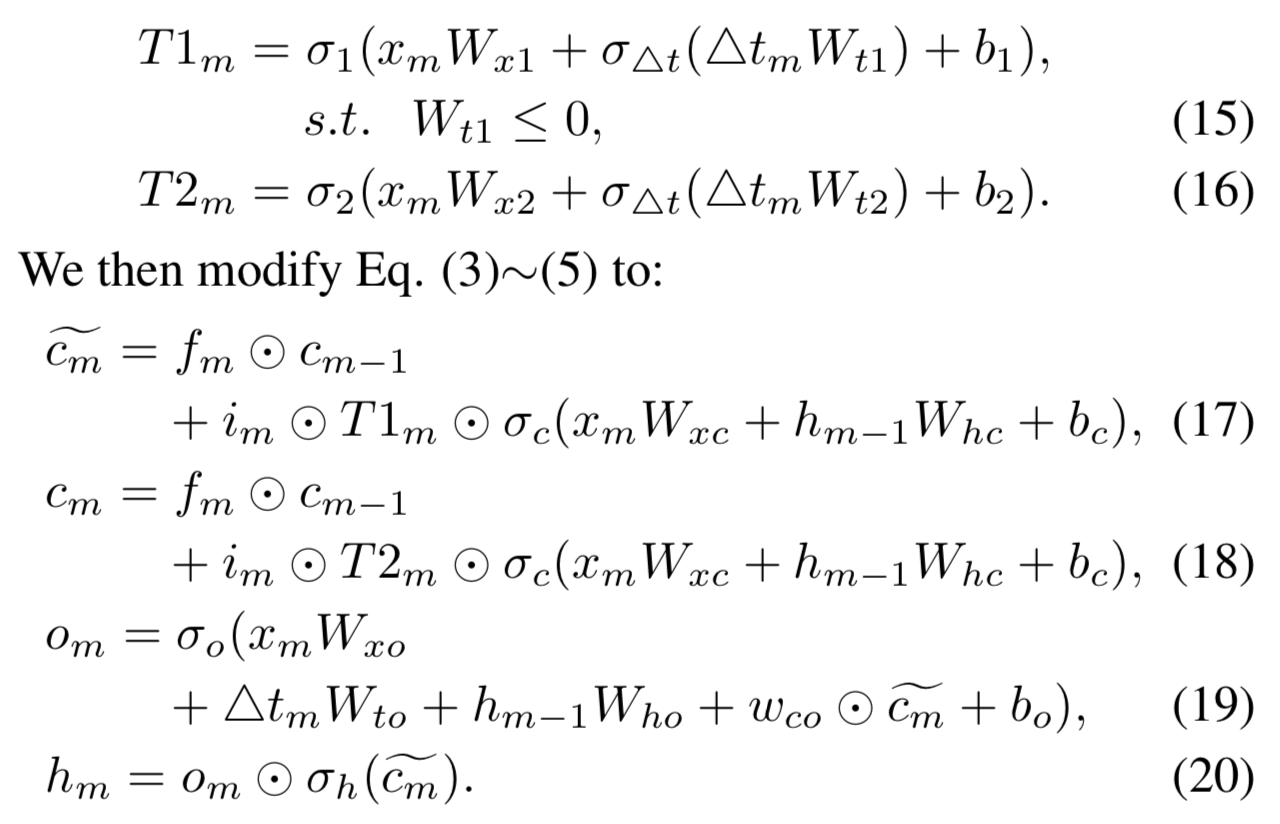 使用了2个Time gate。Time gate1主要用来利用现在的时间间隔来进行现在物品推荐,Time gate2主要用来存储时间间隔为以后的推荐准备。
使用了2个Time gate。Time gate1主要用来利用现在的时间间隔来进行现在物品推荐,Time gate2主要用来存储时间间隔为以后的推荐准备。
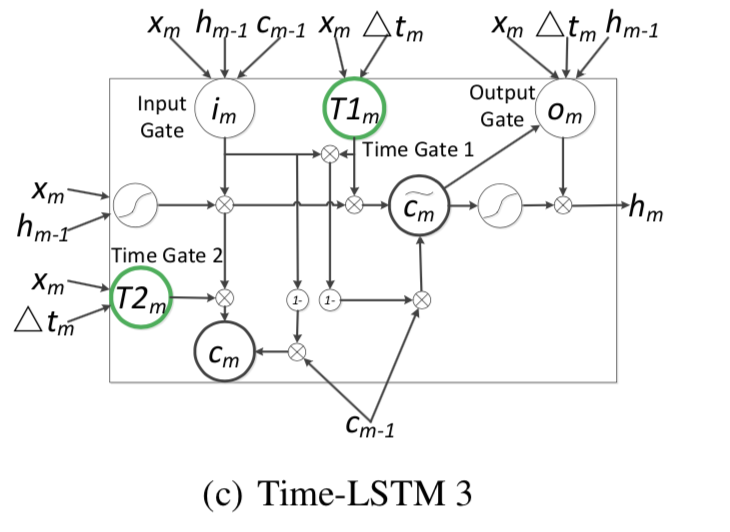
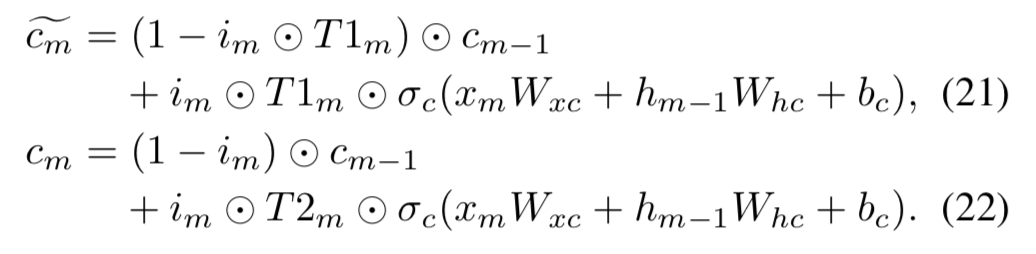 Time LSTM变体3用了耦合的输入门和忘记门。
Time LSTM变体3用了耦合的输入门和忘记门。
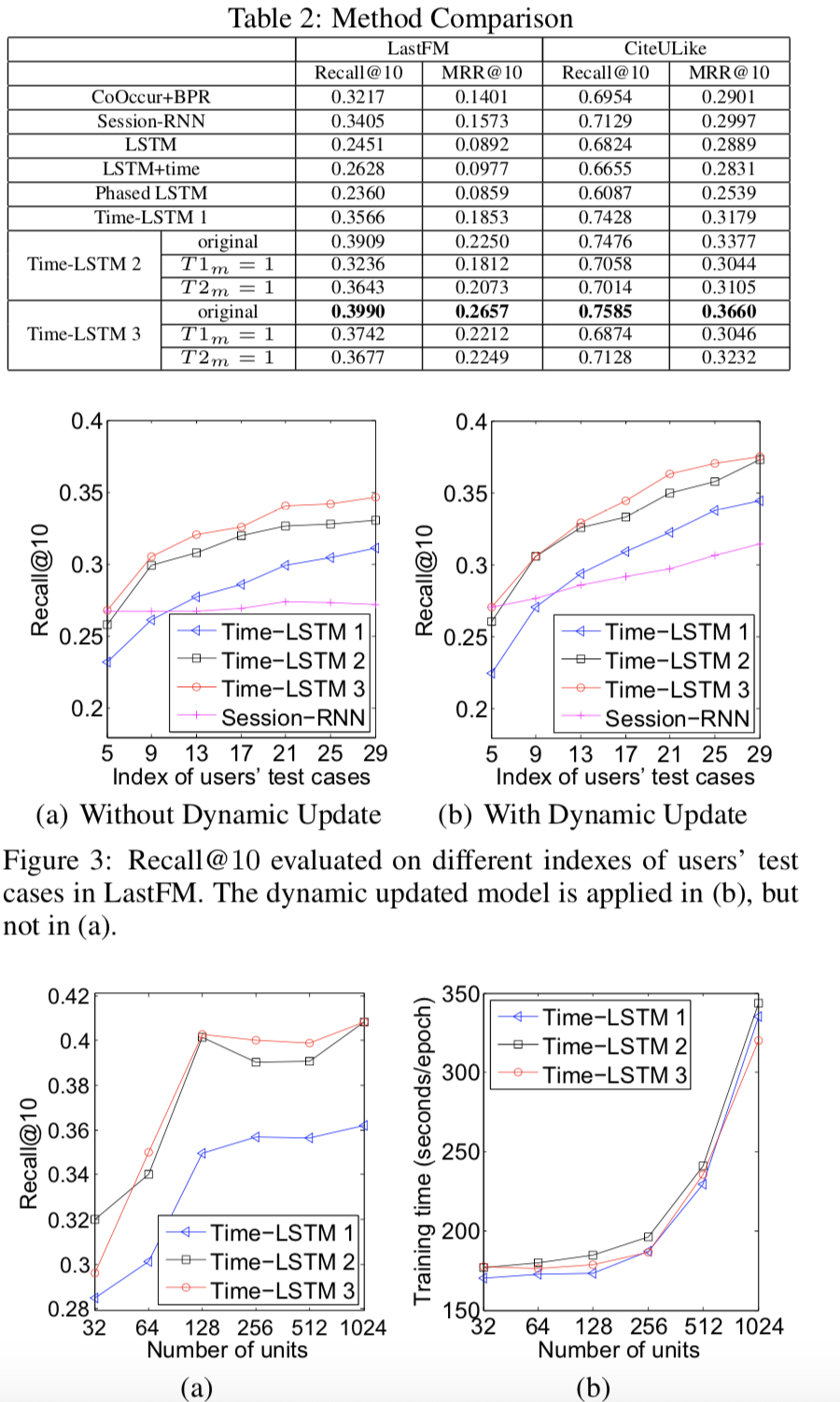 可以看到Time LSTM确实在效果上优于之前的Time-related LSTM方法
可以看到Time LSTM确实在效果上优于之前的Time-related LSTM方法