论文背景
作者针对过往的负采样技术进行总结,提出了新的框架KGPolicy。一般有两种负采样,静态负采样和自适应负采样。
静态采样
静态采样一般选取均匀分布或者按照热度(流行度)负采样。缺点是采样的负样本独立于模型,对模型造成不了什么影响。
自适应负采样
自适应负采样会更加关注难样本。因为这些样本会给模型带来更大的价值。但是这些假设都基于历史。被选取的样本可能在未来出现,所以会损害模型性能。
近期方法
近期方法一般都选取综合的评价,比如展现未点击,点击未转化来加强负采样的有效程度。但依然需要更有效的措施来进行负采样。
模型结构
一般建模的目标都是
$ y_{ui}=f_R(u,i)=r_u^Tr_i $,
根据过去的一些研究,这篇文章使用了BPR损失函数。
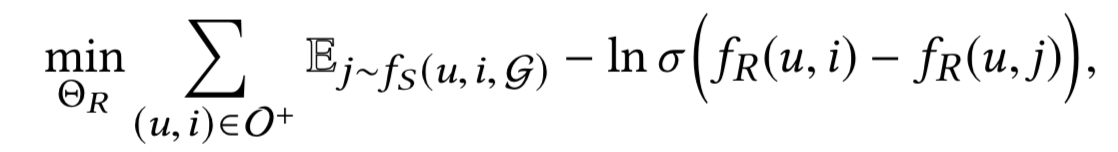
然后这里还涉及到负样本的信息性,衡量标准是梯度的幅值。$ \nabla_{u,i,j} = 1-\sigma(f_R(u,i)-f_R(u,j)) $。所以好的负样本要使得这个数值尽量大。
负样本选取规则
首先定义原子路径:
$ i \rightarrow e^{`} \rightarrow j $
其中 $ i $ 是和 $ u $ 发生过交互关系的,$ j $ 是路径和还没和 $ u $ 发生过交互关系的。
这样做有两点好处:
- 因为 $ i $ 和 $ j $ 都依赖于同样的实体,那么其实它们更加可能相近,所以能提供的负样本信息性更大。
- 可以反映出用户的真实兴趣。说明有足够理由相信用户确实不太对$ j $感兴趣。同样可以继续做路径扩展增加负样本的置信度。
强化学习
强化学习涉及到几个关键问题:
- 动作定义:
$ a_t = (e_t \rightarrow e_t^{`} \rightarrow e_{t+1} ) $ - 状态动态转移:
$ P(s_{t+1} = (u,e_{t+1}) | s_t = (u,e_t),a_t = (e_t \rightarrow e_t^{`} \rightarrow e_{t+1}) )=1 $ - 奖励函数:
预测奖励:$ f_R(u,e_t) g_R(i,e_t) $,考虑相似奖励是为了获得反映用户真实兴趣爱好的样本,表明用户确实不喜欢。
最后总的奖励 = 相似奖励 + 预测奖励 - 目标函数:
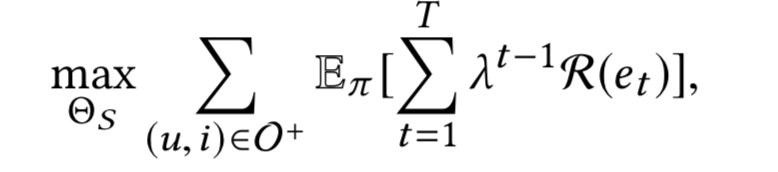
知识图策略网
GraphSage获取节点特征
邻居注意力模块
$ P(a_t|s_t) = P((e_t,e_t^{`})|s_t) * P((e_t^{`},e_{t+1}) | s_t, (e_t,e_t^{`})) $
这个模块由两部分注意力模块构成,分别是(1)知识图谱的邻居注意力和(2)物品的邻居注意力
(1)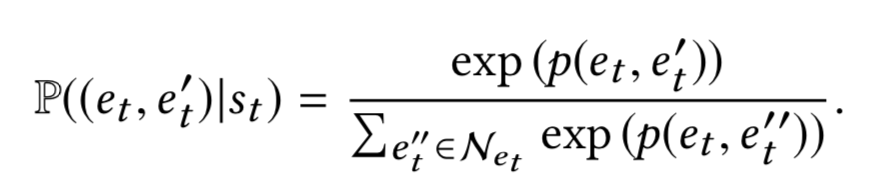
(2)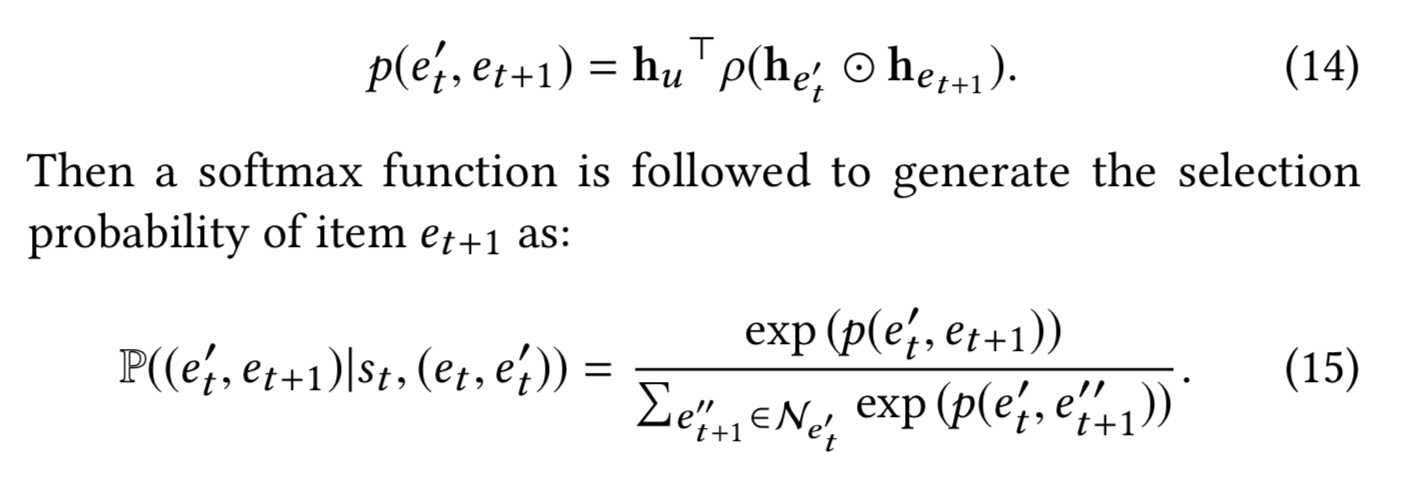
邻居剪枝
为了减少不必要的探索并且保证样本的效果,提出了一个新的策略,具体是
- 先从节点的邻居降采样或者过采样得到一个集合的子集
- 然后从全空间负采样得到另外一些节点保证多样性
- 根据内积打分函数选取与节点最相似的几个节点作为返回结果
这样既降低了时间复杂度也保证了效果
优化
推荐器的优化
固定采样器参数,优化推荐器
采样器的优化
老套路,上reinforce算法做策略梯度
假阴性问题
论文中就说知识图谱的鲁棒性更加高一点,虽然这个问题确实无法避免。
KGPolicy实验
实验为了说明几个问题
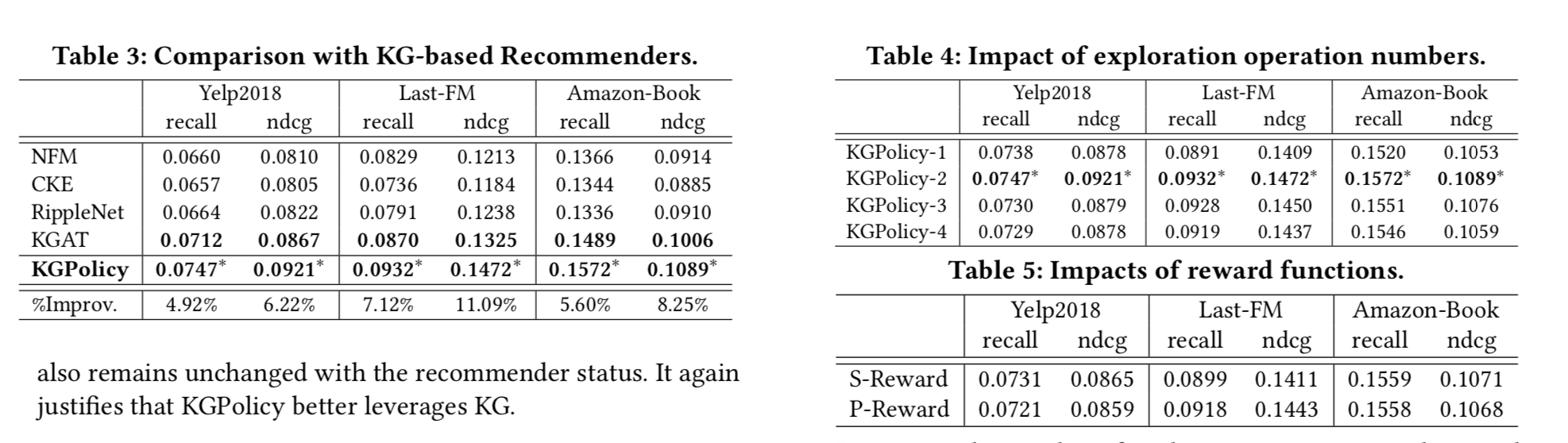
- 和现在的主流方法们比结果怎么样
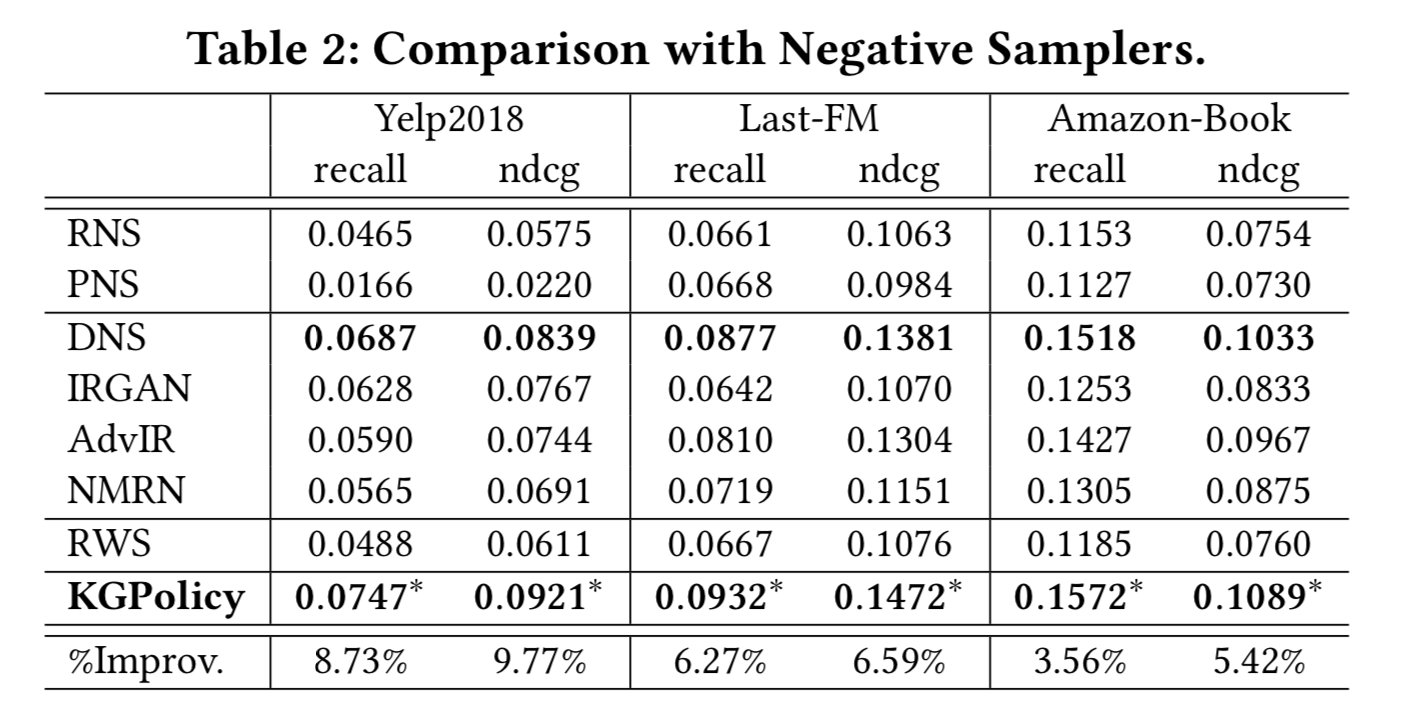
- KGPolicy的参数影响
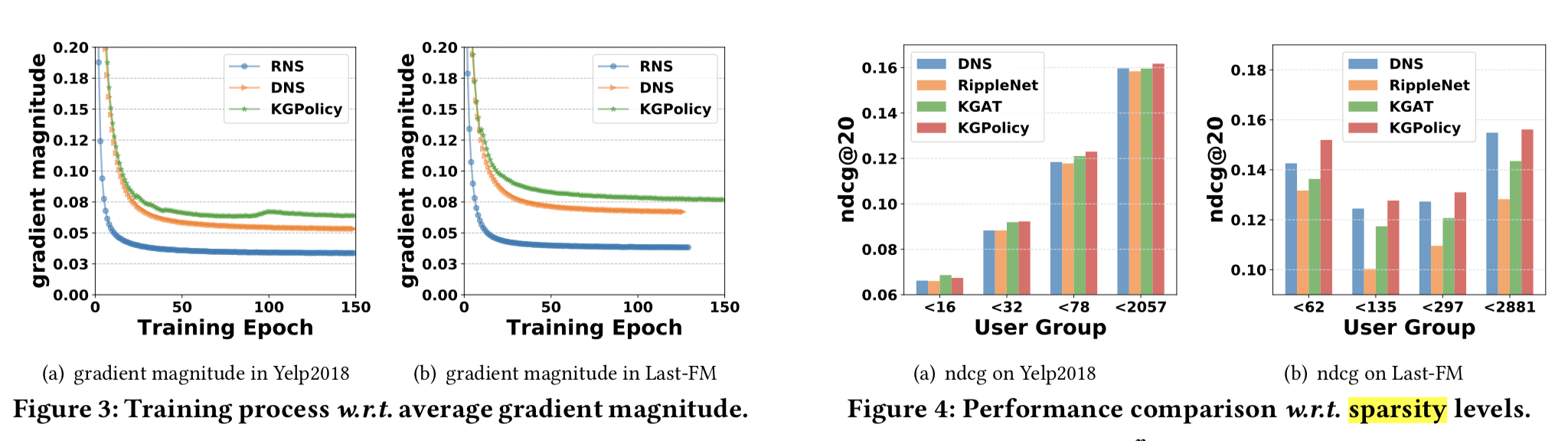
- 负样本的深层次分析
总结
这篇文章其实还是有点东西的。读一读类似的文章对自己还是会有帮助的。