论文背景
现实世界中很多数据特征是缺失的。所以本文希望做半监督学习来一般填充缺失值,一边做点击率的预测任务。
模型结构
图学习模块
Embedding Fusion Layer
这里的符号比较复杂,要先搞清楚一些定义。(对我来说有点混乱)
$ P \in R^{d \times M} $ 用户id的embedding矩阵
$ Q \in R^{d \times N} $ 物品id的embedding矩阵
在第 $ l $ 轮迭代的时候,近似的用户和物品属性矩阵是 $ X^l \in R^{d_x \times M} $ , $ Y^l \in R^{d_y \times N} $ 。
然后第 $ l $ 层的向量是由前一层更新过来的。使用时和属性向量和id embedding向量和在一起用。
$ u_a^{l,0}=[p_a, x_a^l \times W_u] $
$ v_i^{l,0}=[q_i, y_i^l \times W_v] $
第一轮的属性向量就由加权平均填充。
Embedding propagation Layer
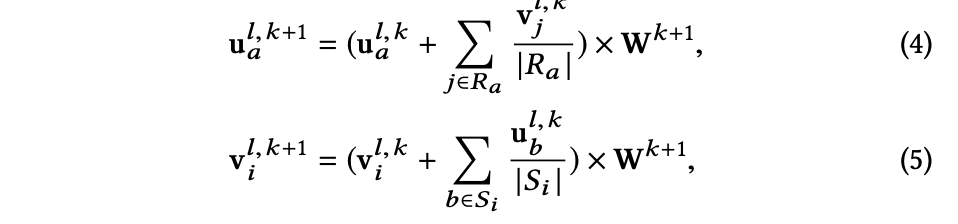

Attribute update module
Prediction Part
Attribute Update Part

Loss
inference loss + recommendation loss
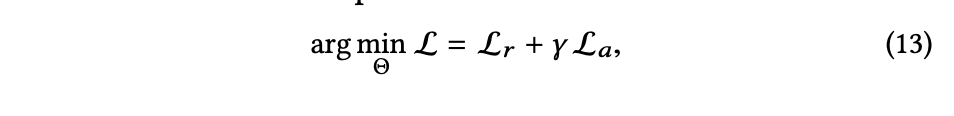
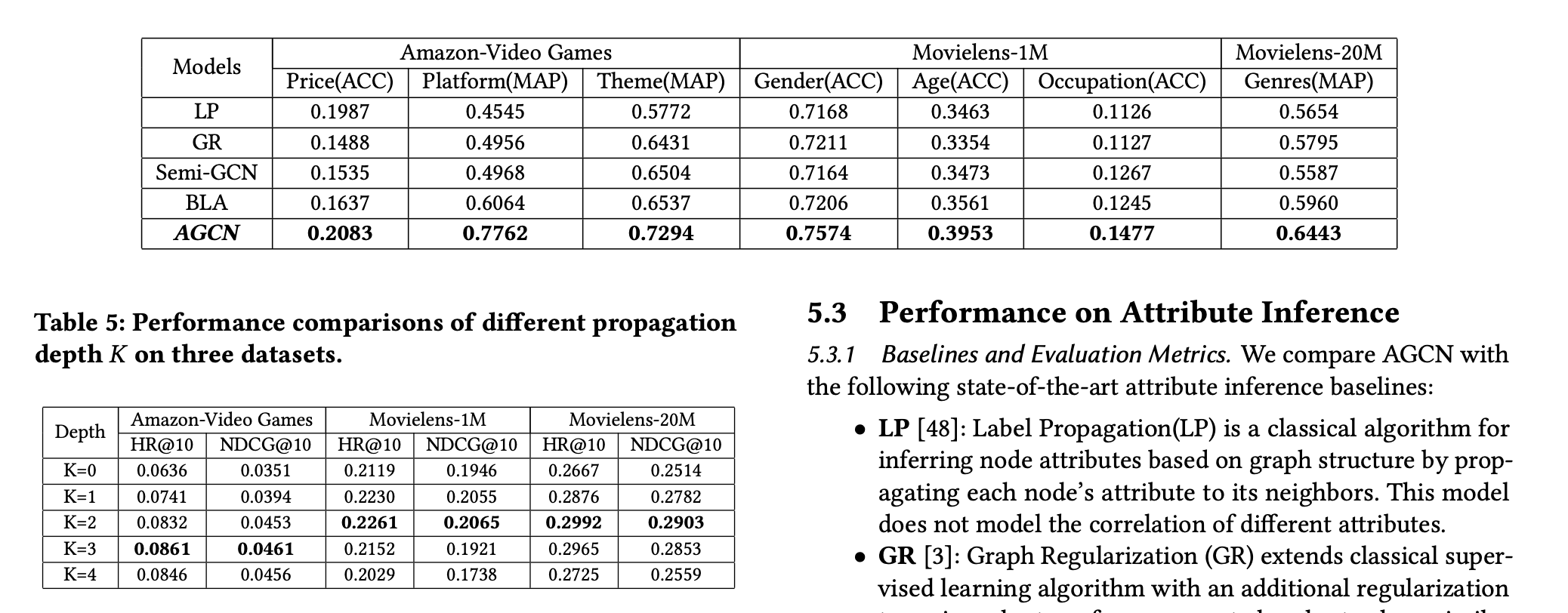
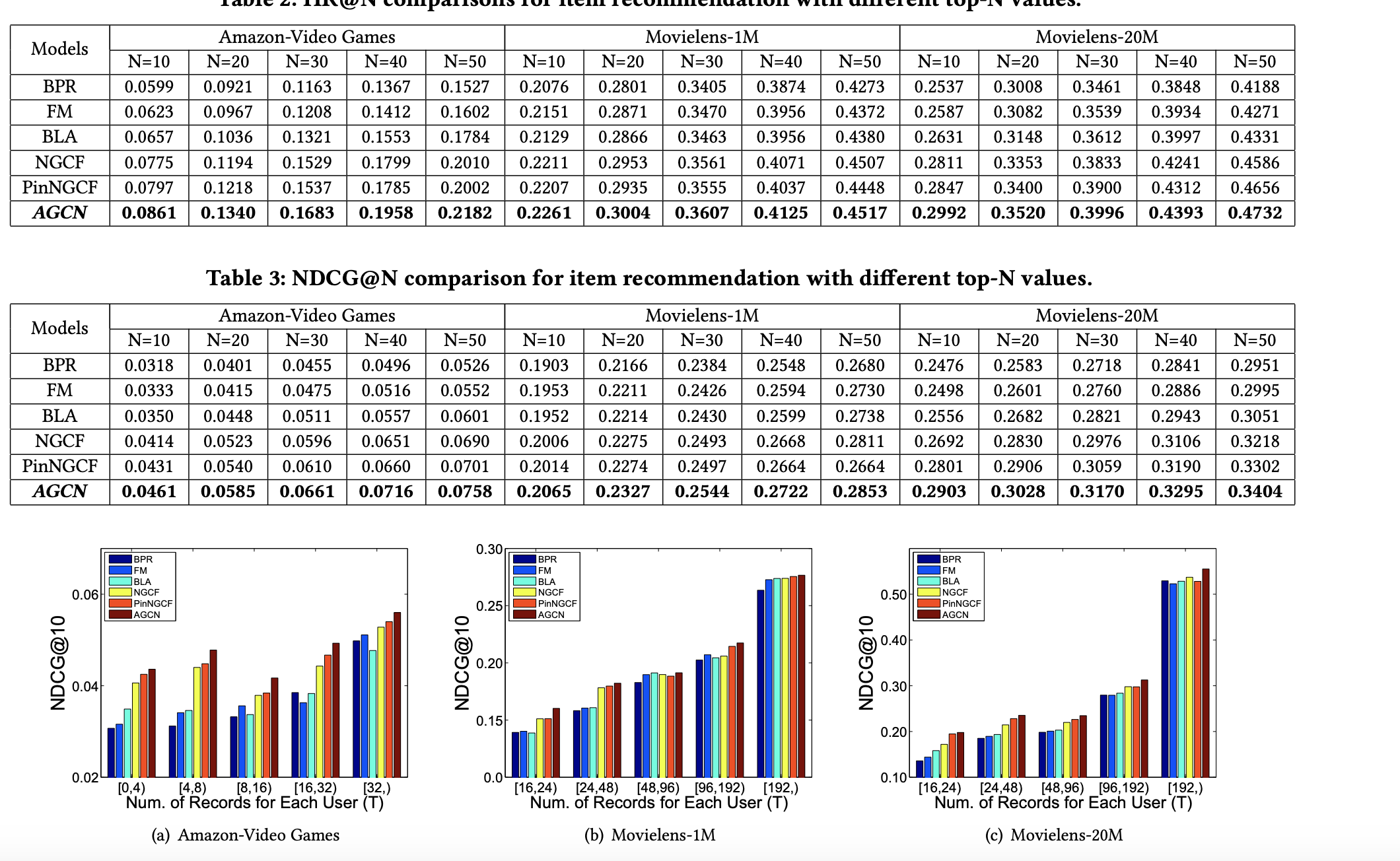
实验结果

总结
其实我在看这篇文章的时候一直在找inference能提升效果的原因分析,但是感觉作者介绍的不是很清楚。总的来讲思路有点像EM,涉及到的问题也是工业界比较棘手的问题。