DDL
MetaStore
Metastore provides information for data layout in hdfs.
HDFS is designated for sequential scans while metastore is designed for random reads and updates.
Hive metastore can be used independently from hive framework.
create
create table tablename;
describe
describe table tablename;
delimiter
Hadoop Mapreduce use tab character as default delimiter.
Hive choose ctrl+A
array ctrl+B
key-value ctrl+C
external table
Data in hdfs will leave unchanged. Metadata will be automatically removed after the Hive Session is closed.
DML
import
load data inpath ‘/local/path/employees-data’ into table employees;
multiple-insert
from employees insert (overwrite) directory ‘path’ select name, salary, address where …
ctas
create table xxx as select xxx,xxx from employees where xx = ‘xx’
Phase
select from: choose from existing columns, could be done with a map phase
where: a map phase
group by: shuffle/sort phase + having: reduce
join: map/reduce side
order by/sort by: reduce
Hive optimization
level partitioning
create table partitioned by (xx,xx,xx)
- partitioned columns go at the end
- partitioned columns order is important
- use configuration parameters
- control empty partitions
set hive.enforce.bucketing=True
map-side join
use power of two
skewed data problem
skewed by user_id on (‘user_id1’,‘unknown’)
REGEX
regex serde
create table xx (xx,xx) ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe’ with serdeproperties (“input.regex” = ‘xxxx’) location ‘xxxx’
regexp_extract
regex optional
- re.match: from the start of a string
- re.search: not necessary from the start of a string
- re.IGNORECASE
- capture group: parenthesis have a special meaning in a regular expression language, can be used to retrieve the content of much later on.
- groups: locate only capturing groups
- non-capturing groups:
example: re.search(“really (?: good|nice)”, …) - some special regex expressions:
\d all digits
\D no digits
\w all alphanumeric characters
\W no alphanumeric characters
\s all whitespace characters
\S no whitespace characters
. any single character
^ beginning of string
$ end of string
view
view is a read-only table generated on the fly than necessary.
create view xxx (
xxx,
xxx
)
as select xxx, xxx from xxx;
view limitations:
- read-only
- extra cpu cycles, but some optimization exists
- meta information fluctuation
function
functions: udf = user defined functions
aggregate functions: udaf
table-generating functions: udtf
show functions
describe functions
udf: map phase
udaf: reduce phase
udtf: both scenarios
explode:
select explode(direct reports) as employee from management
lateral view: merge output from udtf
select manager_name, employee from management lateral view explode(direct reports) lateral_table as employee
streaming

hive window functions
SELECT xx, ROW_NUMBER() OVER (PARTITION BY column_C) from table_name;
SELECT xx, RANK() OVER (PARTITION BY column_C) from table_name;
SELECT xx, DENSE_RANK() OVER (PARTITION BY column_C) from table_name;
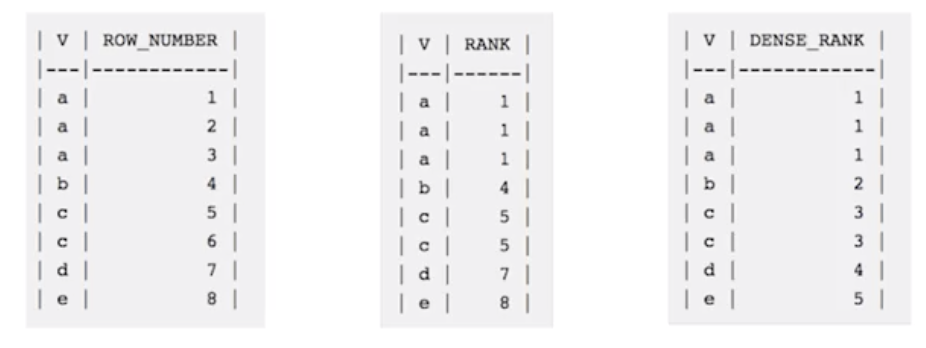
same windows
SELECT column_A, ROW_NUMBER() OVER (PARTITION BY column_C), RANK() OVER (PARTITION BY column_C), DENSE_RANK() OVER (PARTITION BY column_C) FROM table_name; = SELECT column_A, ROW_NUMBER() OVER w, RANK() OVER w, DENSE_RANK() OVER w FROM table_name WINDOW w AS (PARTITION BY column_C);
different windows
SELECT column_A, ROW_NUMBER() OVER (PARTITION BY column_C), RANK() OVER (PARTITION BY column_D), DENSE_RANK() over (
PARITION BY column_E) FROM table_name;